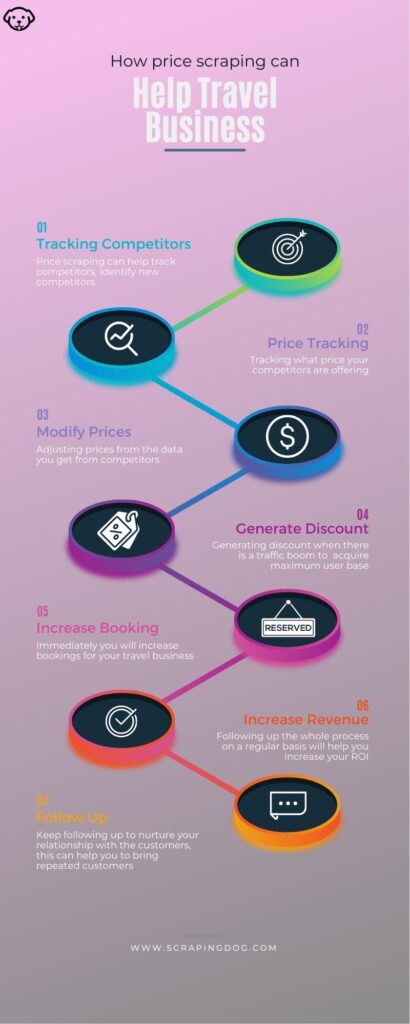
Information Creeping Vs Data Scratching The Essential Distinctions Modern creeping bots are established to much better recognize what the limits of procedures are and follow within the restrictions to avoid legal complications. Because of these technological innovations, the danger of offending are minimal. Web scraping is everything about the data - the information fields you intend to remove from certain web sites. With scratching you generally recognize the target internet sites, you might not know the details page URLs, however you understand the domain names at the very least. The Portable Record Style layout is extremely essential for business who require a significant level of data security. Because both scuffing and crawling are rather related processes, it's no surprise that people obtain confused regarding it. Prices and competitor evaluation-- companies are progressively depending on information scrapers to find up with a pricing method. Scrapers can aid locate, collect, and remove the prices Streamlined Data Extraction information of rivals and track their online actions, price cuts, and prices techniques. Data scuffing objectives to download details, whereas data crawling describes the indexing of web pages. In this situation, the usual scraped information collections are prices, descriptions, testimonials, offers, etc. This might refer to primarily any form of data from a range of various sources-- storage space gadgets, spreadsheets, etc. The information does not need to be from the web or a web page, as we are talking about data scraping in a broader sense, and not specifically web scuffing. The web crawling done by these web crawlers and robots need to be done thoroughly with focus and correct care. The deepness of the infiltration need to not breach the limitations of web sites or personal privacy guidelines when they are creeping various sites. Any type of infringement of such can result in legal actions from whatever large data domain name that could have been upset, which is something that no one wants entangled in. As an example, many individuals post short articles and products throughout different sites. A web spider will have the ability to recognize the duplicate information and not index it once again. This will certainly conserve you time and sources when you prepare to carry out web scratching. One of the most usual use internet spiders is for online search engine, like Google, Bing, or DuckDuckGo, to discover and index details for users to search through. A search engine like Google will certainly make use of web spiders to index websites based upon the web content they have offered for bots to look through. Anti-crawler/scraper devices discover and block scuffing or creeping activities. Scrapers/crawlers are frequently unwanted due to the pressure they cause on internet servers. It can be tiny or big range, depending on the objectives of a scuffing job. Internet crawling can be done by hand by experiencing every one of Extra resources the links on multiple web sites and keeping in mind about which pages contain information pertinent to your search. The ability to scratch a site for helpful data is highly dependent on the shape of the material on a site.
- So first you produce a crawler which will certainly outcome all the page URLs that you appreciate - it can be web pages that remain in a details group on the site or in specific components of the web site.Information scuffing has actually become the ultimate device for business development over the last years.This process includes determining and getting details information factors, such as product rates, product information or customer evaluations, from website or other resources.They do not just check via pages, they accumulate all appropriate info indexing it at the same time, they likewise seek all links to pertinent web pages in the process.Additionally, internet crawlingcomes in helpful for material quality analysis.
What Is Information Crawling?
Discovering the distinctions in between both approaches will aid you determine which approach suits your project, what data you require, and what to do with the data after collecting. It gives them a method to see exactly how a website's content is organized and its inner linking strategy. When the web scraper has every one of the data that you want to gather, it will put that information into a style that you choose. Others give you more advanced alternatives, like returning a JSON item which can be used in API requires additional processing. This procedure is required to filter and different different kinds of raw data from various resources right into something usable and informative. Data scuffing is much more precise than information abounding what it collects. It can draw things out, such as asset prices, and more difficult to reach information.What Is Information Scratching?
Threat, brand, and public relations administration-- scuffing can aid a company screen brand points out, check marketers' landing pages, boost ad performance, and discover ad fraud to take the required actions. To come down to the base of the web creeping vs internet scuffing fight, we must initially specify both concepts. Regardless of the sector, the Internet is an excellent resource of important information.Deta's Space OS Aims To Build the First 'Personal Cloud Computer' - Slashdot
Deta's Space OS Aims To Build the First 'Personal Cloud Computer'.
Posted: Tue, 10 Oct 2023 07:00:00 GMT [source]